Table of Contents
I know, I know—you’re probably not in the mood for another AI post. Trust me, this one delivers.
This is the story of how a candid conversation with my long-time mentor turned into three new tools that fundamentally change how AI agents understand Aspire.
💬 The conversation that started it all
David Fowler has always been direct with me—which I’ve come to not only expect but genuinely adore.
We were in the midst of a rebrand, replatforming docs, and reimagining Aspire for what felt like the 13th time. During one of our conversations, I was explaining how we could improve the developer experience when building Aspire apps with AI assistance. That’s when we discovered the real problem.
🤔 The problem: AI doesn’t know where to look
When developers rely on AI to help build Aspire apps, something frustrating kept happening.
The AI would recommend generic .NET patterns. It would reference learn.microsoft.com for documentation. It would suggest dotnet run instead of aspire run. It would recommend outdated NuGet packages. It would hallucinate APIs that don’t exist. FFS 🤬!
Why? Because we were ”.NET Aspire” far longer than we’ve been just “Aspire.” LLMs are trained on historical data, and they’re slow to catch up. The models learned .NET Aspire patterns: the .NET CLI, learn.microsoft.com, the old conventions. Now that we’re simply Aspire with aspire.dev as our documentation home, we needed to teach them the new way.
💡 The solution: feed the AI real docs
The answer was staring us in the face.
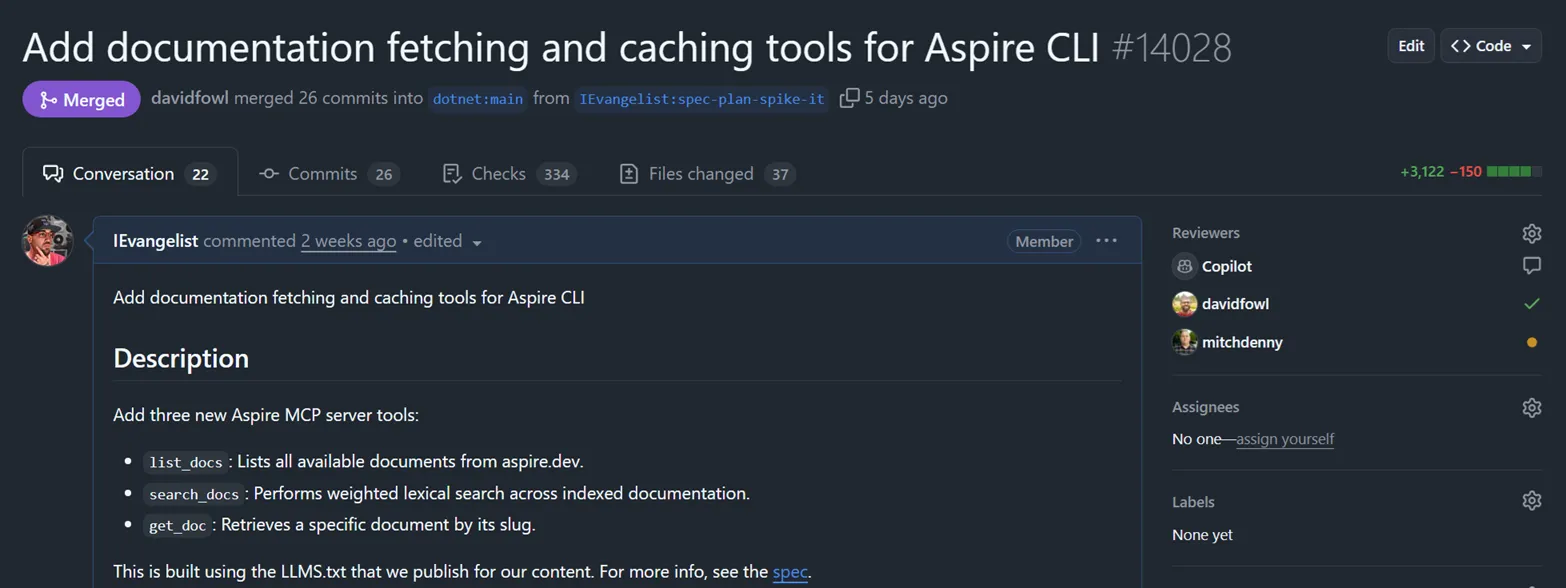
We needed to surface Aspire documentation directly to AI agents through the Aspire MCP (Model Context Protocol) server. Not just links—the actual content, indexed and searchable. So I wrote three new tools:
list_docs: Lists all available documents from aspire.devsearch_docs: Performs weighted lexical search across indexed documentationget_doc: Retrieves a specific document by its slug
These tools solve a real problem: feeding LLMs meaningful guidance grounded in official documentation.
🦸 Standing on the shoulders of llms.txt
Here’s where it gets interesting.
Since day one, aspire.dev has shipped with llms.txt support—thanks to an amazing Starlight maintainer, Chris Swithinbank (delucis). His starlight-llms-txt plugin follows the official llms.txt specification and generates LLM-friendly documentation during the site build process.
The llms.txt spec is brilliant in its simplicity:
- A standardized
/llms.txtmarkdown file for LLM consumption - Brief background information, guidance, and links to detailed content
- A format that’s both human-readable and machine-parseable
We configure a few pages to ignore, and from there it’s off to the races. The result? A curated, LLM-friendly version of our docs at aspire.dev/llms-small.txt.
🏗️ The architecture
Let me walk you through how this all works.
Tools
list_docs: Lists all available documentationsearch_docs: Performs weighted lexical searchget_doc: Retrieves specific document by slug
Services
IDocsFetcher: HTTP client for aspire.dev docs with ETagIDocsCache: IMemoryCache wrapper with ETag storageIDocsIndexService: Pre-indexing and weighted lexical searchIDocsSearchService: High-level search API
Parsers
LlmsTxtParser: Async parallel parser for llms.txt format
⚙️ How it works
- Eager indexing: When the MCP server starts, it immediately begins fetching and indexing aspire.dev documentation in the background—usually before the user even makes a request.
- ETag-based caching: The fetcher uses HTTP ETags for conditional requests—no re-downloading unchanged content.
- Weighted lexical search: Documents are scored using field weights (titles weighted 10x, summaries 8x, headings 6x, code 5x).
- Zero external dependencies: No embedding provider needed. Pure lexical search that just works.
🔤 Why lexical search over embeddings?
Embeddings are costly upfront. We may revisit them later to improve recall, but for now, lexical search nails the use cases we care about.
Queries are:
- Term-driven: “connection string”, “workload identity”
- Section-oriented: “configuration”, “examples”
- Name-exact: “Redis resource”, “AddServiceDefaults”
When someone asks about AddPostgresContainer, they mean exactly that method name. Embeddings get fuzzy. Lexical search nails it.
✨ The impact on UX
This pull request fundamentally changes how AI agents help developers.
Before
- ❌ AI recommends
dotnet run - ❌ AI suggests outdated NuGet packages
- ❌ AI references learn.microsoft.com for Aspire
- ❌ AI hallucinates non-existent APIs
After
- ✅ AI recommends
aspire run - ✅ AI knows current package versions from docs
- ✅ AI references aspire.dev as the source of truth
- ✅ AI provides correct, documented API usage
🔧 The tools in action
list_docs
Lists all available documents from aspire.dev. No parameters required.
{ "type": "object", "properties": {}, "additionalProperties": false, "description": "Lists all available documentation from aspire.dev. No parameters required."}search_docs
Performs weighted lexical search across indexed documentation. Pass a query, get ranked results back.
{ "type": "object", "properties": { "query": { "type": "string", "description": "The search query to find relevant documentation." }, "topK": { "type": "integer", "description": "Number of results to return (default: 5, max: 20)." } }, "required": ["query"]}get_doc
Retrieves a specific document by its slug. Matching is case-insensitive, and you get the full document content.
{ "type": "object", "properties": { "slug": { "type": "string", "description": "The document slug (URL-friendly identifier)." } }, "required": ["slug"]}🔬 Implementation details
The weighted search scoring is carefully tuned.
| Field | Weight |
|---|---|
| Title (H1) | 10.0x |
| Summary | 8.0x |
| Section Heading | 6.0x |
| Code blocks | 5.0x |
| Body text | 1.0x |
Additional scoring bonuses:
- Word boundary match: +0.5
- Multiple occurrences: +0.25 per occurrence (max 3)
- Code identifier match: +0.5
The parser uses ReadOnlySpan<char> for zero-allocation parsing and ArrayPool<char> for slug generation. Performance matters when you’re indexing documentation at startup.
🧩 Beyond MCP: reusable services
Here’s the thing—we built a very small amount of MCP-specific code. For the most part, we built reusable services that happen to be exposed through MCP.
The IDocsIndexService, IDocsSearchService, IDocsFetcher, and IDocsCache are all standalone abstractions. They understand how to fetch, parse, cache, and search aspire.dev documentation. The MCP tools are just one consumer.
This opens up possibilities:
- CLI command:
aspire docs search "redis caching"could query the same index - AI skills: Semantic Kernel or AutoGen agents could use these services directly
- IDE extensions: A VS Code extension could surface doc search without leaving the editor
- Build-time validation: Verify that code samples reference documented APIs
The architecture is intentionally decoupled. Today it’s MCP. Tomorrow it could be anything that needs programmatic access to Aspire documentation.
📊 Architecture diagrams
Let’s break down the architecture into digestible pieces.
Request flow
Here’s what happens when an AI agent uses the docs tools:
Tools → services
The tools use different services based on their needs:
Fetching and parsing
The index service coordinates fetching from aspire.dev and parsing the LLMS.txt format:
Caching with ETags
The fetcher uses HTTP ETags to avoid re-downloading unchanged content:
🔮 What’s next?
This is just the beginning.
Future considerations include:
- Full documentation support: Currently using
llms-small.txtfor abridged docs—could addllms-full.txtfor comprehensive documentation. - Sitemap integration: Use
sitemap.xmlto discover all docs pages for more complete indexing, and map slugs back to aspire.dev URLs. - Disk persistence: Serialize parsed documents to disk for faster startup.
- Search improvements: TF-IDF or BM25 for more sophisticated ranking, plus fuzzy matching for typo tolerance.
🎬 Wrapping up
Sometimes the best solutions come from recognizing what’s already there. We had LLMS.txt. We had the MCP server. We just needed to connect them.
Thanks to David Fowler for the direct feedback that sparked this work, and to Chris Swithinbank for the incredible starlight-llms-txt plugin that makes it all possible. If you’re using AI to build Aspire apps, these tools should make your experience noticeably better.
The AI now has access to the same documentation you do—and it knows to use it.
Check out the full pull request on GitHub.
Happy coding, friends! 🚀